
2. Replication of results from paper: “Predicting yeast synthetic lethal genetic interactions using protein domains”¶
Authors: Bo Li, Feng Luo,School of Computing,Clemson University,Clemson, SC, USA
e-mail: bol, luofeng@clemson.edu
year:2009
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
import seaborn as sns
import matplotlib.cm as cm
import scipy as scipy
import random
2.1. Importing datasets¶
2.1.1. Link to the github repo where the datasets to be downloaded:¶
import os
script_dir = os.path.dirname('__file__') #<-- absolute dir the script is in
rel_path_SL = "datasets/data-synthetic-lethals.xlsx"
rel_path_nSL="datasets/data-positive-genetic.xlsx"
rel_path_domains="datasets/proteins-domains-from-Pfam.xlsx"
abs_file_path_SL = os.path.join(script_dir, rel_path_SL)
abs_file_path_nSL = os.path.join(script_dir, rel_path_nSL)
abs_file_path_domains = os.path.join(script_dir, rel_path_domains)
# os.chdir('mini_book/docs/') #<-- for binder os.chdir('../')
# os.chdir('../')
my_path_sl= abs_file_path_SL
my_path_non_sl=abs_file_path_nSL
my_path_domains=abs_file_path_domains
data_sl=pd.read_excel(my_path_sl,header=0)
data_domains=pd.read_excel(my_path_domains,header=0,index_col='Unnamed: 0')
data_domains=data_domains.dropna()
data_nonsl=pd.read_excel(my_path_non_sl,header=0)
2.2. Building the feature matrix¶
One matrix for true SL where each row is one pair of SL. Every raw will be a vector of 0,1 or 2 depending on the comparison with the domain list. For row i the jth element = 0 if the jth element of the domain list is not in neither protein A and B, 1, if it is in one of them and 2 if it is in both of them .
2.2.1. Building the list of proteins domains id per protein pair separately :¶
List of protein A: Search for the Sl/nSL database the query gene name and look in the protein domain database which protein domains id has each of those queries.
List of protein B: Search for the Sl/nSL database the target gene name of the previous query and look in the protein domain database which protein domains id has each of those target genes.
# Selecting the meaningful columns in the respective dataset
domain_id_list=data_domains['domain-name']
query_gene=data_sl['gene-query-name']
target_gene=data_sl['gene-target-name']
query_gene_nonlethal=data_nonsl['gene-query-name']
target_gene_nonlethal=data_nonsl['gene-target-name']
# Initialising the arrays
protein_a_list=[]
protein_b_list=[]
protein_a_list_non=[]
protein_b_list_non=[]
population = np.arange(0,len(data_sl))
# For loop for 10000 pairs sampled randomly from the SL/nSl pair list , and creating a big array of proteind domains id per protein pair
for m in random.sample(list(population), 100):
protein_a=data_domains[data_domains['name']==query_gene[m]]
protein_b=data_domains[data_domains['name']==target_gene[m]]
protein_a_list.append(protein_a['domain-name'].tolist())
protein_b_list.append(protein_b['domain-name'].tolist())
protein_a_non=data_domains[data_domains['name']==query_gene_nonlethal[m]]
protein_b_non=data_domains[data_domains['name']==target_gene_nonlethal[m]]
protein_a_list_non.append(protein_a_non['domain-name'].tolist())
protein_b_list_non.append(protein_b_non['domain-name'].tolist())
print('We are going to analyze',len((protein_a_list)) ,'protein pairs, out of',len(data_sl),'SL protein pairs')
print('We are going to analyze',len((protein_a_list_non)) ,'protein pairs, out of',len(data_nonsl),'positive protein pairs')
We are going to analyze 100 protein pairs, out of 17871 SL protein pairs
We are going to analyze 100 protein pairs, out of 43340 positive protein pairs
2.2.2. Postprocessing #1: Remove protein pairs from study if either protein in the pair does not contain any domain¶
def remove_empty_domains(protein_list_search,protein_list_pair):
index=[]
for i in np.arange(0,len(protein_list_search)):
if protein_list_search[i]==[] or protein_list_pair[i]==[]:
index.append(i) ## index of empty values for the protein_a_list meaning they dont have any annotated domain
y=[x for x in np.arange(0,len(protein_list_search)) if x not in index] # a list with non empty values from protein_a list
protein_list_search_new=[]
protein_list_pair_new=[]
for i in y:
protein_list_search_new.append(protein_list_search[i])
protein_list_pair_new.append(protein_list_pair[i])
return protein_list_search_new,protein_list_pair_new
## evaluating the function
protein_a_list_new,protein_b_list_new=remove_empty_domains(protein_a_list,protein_b_list)
protein_a_list_non_new,protein_b_list_non_new=remove_empty_domains(protein_a_list_non,protein_b_list_non)
print('The empty domain in the SL were:', len(protein_a_list)-len(protein_a_list_new), 'out of', len(protein_a_list),'domains')
print('The empty domain in the nSL were:', len(protein_a_list_non)-len(protein_a_list_non_new), 'out of', len(protein_a_list_non),'domains')
The empty domain in the SL were: 8 out of 100 domains
The empty domain in the nSL were: 24 out of 100 domains
2.2.3. Feature engineering: Select from each ordered indexes of domain id list which of them appear once, in both or in any of the domains of each protein pair¶
2.2.3.1. Define function get_indexes¶
get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y] # a function that give the index of whether a value appear in array or not
a=[1,2,2,4,5,6,7,8,9,10]
get_indexes(2,a)
[1, 2]
def feature_building(protein_a_list_new,protein_b_list_new):
x = np.unique(domain_id_list)
## To avoid taking repeated domains from one protein of the pairs , lets reduced the domains of each protein from the pairs to their unique members
protein_a_list_unique=[]
protein_b_list_unique=[]
for i in np.arange(0,len(protein_a_list_new)):
protein_a_list_unique.append(np.unique(protein_a_list_new[i]))
protein_b_list_unique.append(np.unique(protein_b_list_new[i]))
protein_feat_true=np.zeros(shape=(len(x),len(protein_a_list_unique)))
pair_a_b_array=[]
for i in np.arange(0,len(protein_a_list_unique)):
index_a=[]
pair=[protein_a_list_unique[i],protein_b_list_unique[i]]
pair_a_b=np.concatenate(pair).ravel()
pair_a_b_array.append(pair_a_b)
j=0
for i in pair_a_b_array:
array,index,counts=np.unique(i,return_index=True,return_counts=True)
for k,m in zip(counts,array):
if k ==2:
protein_feat_true[get_indexes(m,x),j]=2
if k==1:
protein_feat_true[get_indexes(m,x),j]=1
j=j+1
return protein_feat_true
protein_feat_true=feature_building(protein_b_list_new=protein_b_list_new,protein_a_list_new=protein_a_list_new)
protein_feat_true_pd=pd.DataFrame(protein_feat_true.T)
protein_feat_non_true=feature_building(protein_b_list_new=protein_b_list_non_new,protein_a_list_new=protein_a_list_non_new)
protein_feat_non_true_pd=pd.DataFrame(protein_feat_non_true.T)
2.2.4. How many ones and twos are in each dataset¶
index_2_true=protein_feat_true_pd.where(protein_feat_true_pd==2)
index_2_true_count=index_2_true.count(axis=1).sum()
index_1_true=protein_feat_true_pd.where(protein_feat_true_pd==1)
index_1_true_count=index_1_true.count(axis=1).sum()
index_2_nontrue=protein_feat_non_true_pd.where(protein_feat_non_true_pd==2)
index_2_nontrue_count=index_2_nontrue.count(axis=1).sum()
index_1_nontrue=protein_feat_non_true_pd.where(protein_feat_non_true_pd==1)
index_1_nontrue_count=index_1_nontrue.count(axis=1).sum()
print('fraction of twos in the SL array is',index_2_true_count/(len(protein_feat_true_pd.index)*len(protein_feat_true_pd.columns)))
print('fraction of ones in the SL array is',index_1_true_count/(len(protein_feat_true_pd.index)*len(protein_feat_true_pd.columns)))
print('fraction of twos in the PI array is',index_2_nontrue_count/(len(protein_feat_non_true_pd.index)*len(protein_feat_non_true_pd.columns)))
print('fraction of ones in the PI array is',index_1_nontrue_count/(len(protein_feat_non_true_pd.index)*len(protein_feat_non_true_pd.columns)))
fraction of twos in the SL array is 3.593244699964068e-05
fraction of ones in the SL array is 0.0009989220265900108
fraction of twos in the PI array is 8.69943453675511e-06
fraction of ones in the PI array is 0.0008264462809917355
2.2.4.1. Bar plot to visualize these numbers¶
plt.bar(['fraction of 2 in the nSL','fraction of 1 in the nSL'],[index_2_nontrue_count/(len(protein_feat_non_true_pd.index)*len(protein_feat_non_true_pd.columns)),index_1_nontrue_count/(len(protein_feat_non_true_pd.index)*len(protein_feat_non_true_pd.columns))],alpha=0.6,color=['blue','lightblue']),
plt.bar(['fraction of 2 in SL ','fraction of 1 in SL'],[index_2_true_count/(len(protein_feat_true_pd.index)*len(protein_feat_true_pd.columns)),index_1_true_count/(len(protein_feat_true_pd.index)*len(protein_feat_true_pd.columns))],alpha=0.6,color=['coral','lightcoral'])
plt.ylabel('Fraction from the population')
plt.yscale('log')
plt.xticks(rotation=40)
([0, 1, 2, 3], <a list of 4 Text xticklabel objects>)
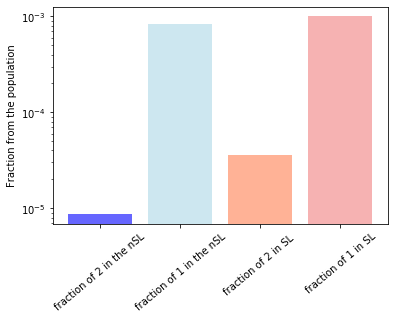
2.2.4.2. Adding the labels(response variables) to each dataset¶
protein_feat_true_pd['lethality']=np.ones(shape=(len(protein_a_list_new)))
protein_feat_non_true_pd['lethality']=np.zeros(shape=(len(protein_a_list_non_new)))
2.2.4.3. Joining both datasets¶
feature_post=pd.concat([protein_feat_true_pd,protein_feat_non_true_pd],axis=0)
feature_post=feature_post.set_index(np.arange(0,len(protein_a_list_new)+len(protein_a_list_non_new)))
print('The number of features are:',feature_post.shape[1])
print('The number of samples are:',feature_post.shape[0])
The number of features are: 3026
The number of samples are: 168
2.2.5. Postprocessing and exploration of the feature matrix of both datasets¶
mean=feature_post.T.describe().loc['mean']
std=feature_post.T.describe().loc['std']
lethality=feature_post['lethality']
corr_keys=pd.concat([mean,std,lethality],axis=1)
2.2.6. Viz of the stats¶
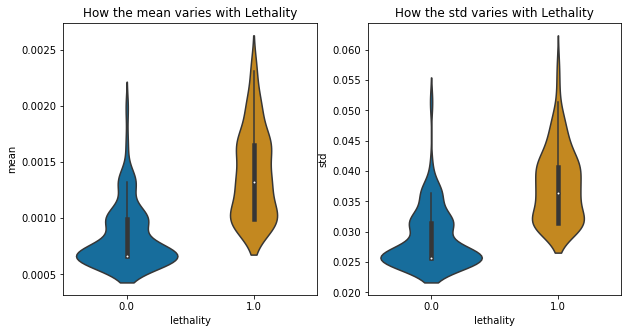
fig, axs = plt.subplots(ncols=2, figsize=(10,5))
a=sns.violinplot(x="lethality", y="mean", data=corr_keys,ax=axs[0],palette='colorblind')
a.set_title('How the mean varies with Lethality')
b=sns.violinplot(x="lethality", y="std", data=corr_keys,ax=axs[1],palette='colorblind')
b.set_title('How the std varies with Lethality')
##plt.savefig('violinplot-mean-std-with-lethality.png', format='png',dpi=300,transparent='true')
Text(0.5, 1.0, 'How the std varies with Lethality')
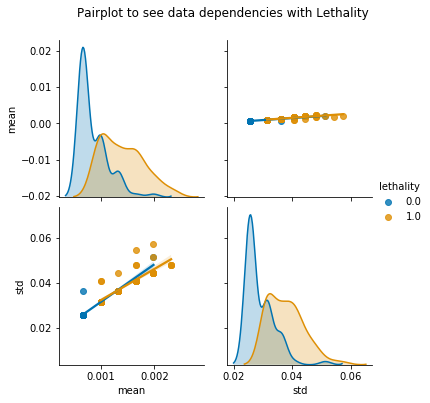
pair=sns.pairplot(corr_keys,hue='lethality',diag_kind='kde',kind='reg',palette='colorblind')
pair.fig.suptitle('Pairplot to see data dependencies with Lethality',y=1.08)
##plt.savefig('Pairplot-to-see-data-dependencies-with-Lethality.png',format='png',dpi=300,transparent='True', bbox_inches='tight')
Text(0.5, 1.08, 'Pairplot to see data dependencies with Lethality')
a=scipy.stats.pearsonr(corr_keys['mean'],corr_keys['lethality'])
p_value_corr=defaultdict(dict)
columns=['mean','std']
for i in columns:
tmp=scipy.stats.pearsonr(corr_keys[i],corr_keys['lethality'])
p_value_corr[i]['corr with lethality']=tmp[0]
p_value_corr[i]['p-value']=tmp[1]
p_value_corr_pd=pd.DataFrame(p_value_corr)
corr = corr_keys.corr()
import matplotlib.cm as cm
sns.heatmap(corr, vmax=1,vmin=-1 ,square=True,cmap=cm.PRGn,cbar_kws={'label':'Pearson corr'})
##plt.savefig('Heatmap-Pearson-corr-mean-std-lethality.png', format='png',dpi=300,transparent='true',bbox_inches='tight')
<matplotlib.axes._subplots.AxesSubplot at 0x186c6692388>
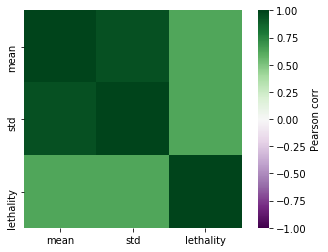
2.3. Separate features from labels to set up the data from the ML workflow¶
X, y = feature_post.drop(columns=["lethality"]), feature_post["lethality"]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state= 0)
print ('Train set:', X_train.shape, y_train.shape)
print ('Test set:', X_test.shape, y_test.shape)
Train set: (117, 3025) (117,)
Test set: (51, 3025) (51,)
2.3.1. Choosing the best SVM model¶
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
parameters = [{'C': [1, 10, 100], 'kernel': ['rbf'], 'gamma': ['auto','scale']}]
search = GridSearchCV(SVC(), parameters, n_jobs=-1, verbose=1)
search.fit(X_train, y_train)
Fitting 5 folds for each of 6 candidates, totalling 30 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 4.0s finished
GridSearchCV(estimator=SVC(), n_jobs=-1,
param_grid=[{'C': [1, 10, 100], 'gamma': ['auto', 'scale'],
'kernel': ['rbf']}],
verbose=1)
best_parameters = search.best_estimator_
print(best_parameters)
SVC(C=10)
2.3.2. Training with the best model¶
2.3.2.1. Note : This learning is without applying reduction of dimensionality with PCA . This make the SVM not optimized at all.¶
Later we shall see how this svm is affected after PCA transformation to the data .
from sklearn import svm
clf = svm.SVC(C=10, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False).fit(X_train, y_train)
clf.score(X_test, y_test)
0.5882352941176471
2.3.3. Saving the model¶
from joblib import dump, load
dump(clf, '../model_SVC_C_10_gamma_scale_kernel_rbf_10000x3072_matrix.joblib')
['../model_SVC_C_10_gamma_scale_kernel_rbf_10000x3072_matrix.joblib']
2.3.4. Loading the model¶
from joblib import dump, load
clf = load('../model_SVC_C_10_gamma_scale_kernel_rbf_10000x3072_matrix.joblib')
2.3.5. Making predictions¶
from sklearn import metrics
from sklearn.metrics import log_loss
from sklearn.metrics import jaccard_score
y_pred = clf.predict(X_test)
# print('Train set Accuracy: ', metrics.accuracy_score(y_train, clf.predict(X_train)))
print('The mean squared error is =',metrics.mean_squared_error(y_test,y_pred))
print('Test set Accuracy: ', metrics.accuracy_score(y_test, y_pred))
print('The Jaccard index is =', jaccard_score(y_test, y_pred))
# Jaccard similarity coefficient, defined as the size of the intersection divided by the size of the union of two label sets. The closer to 1 the better the classifier
print('The log-loss is =',log_loss(y_test,y_pred))
# how far each prediction is from the actual label, it is like a distance measure from the predicted to the actual , the classifer with lower log loss have better accuracy
print('The f1-score is =',metrics.f1_score(y_test,y_pred))
# The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal.
# Model Precision: what percentage of positive tuples are labeled as such?
print("Precision:",metrics.precision_score(y_test, y_pred))
# Model Recall: what percentage of positive tuples are labelled as such?
print("Recall:",metrics.recall_score(y_test, y_pred))
The mean squared error is = 0.4117647058823529
Test set Accuracy: 0.5882352941176471
The Jaccard index is = 0.43243243243243246
The log-loss is = 14.222021565977577
The f1-score is = 0.6037735849056604
Precision: 0.5925925925925926
Recall: 0.6153846153846154
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, target_names=['NonSl','SL']))
precision recall f1-score support
NonSl 0.58 0.56 0.57 25
SL 0.59 0.62 0.60 26
accuracy 0.59 51
macro avg 0.59 0.59 0.59 51
weighted avg 0.59 0.59 0.59 51
import sklearn.metrics as metrics
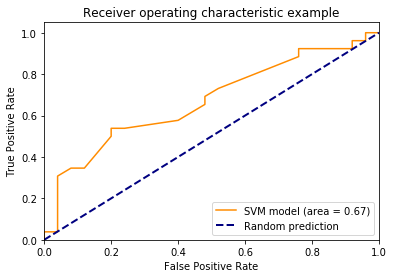
scores=clf.decision_function(X_test)
fpr, tpr, thresholds = metrics.roc_curve(y_test, scores)
area=metrics.auc(fpr,tpr)
plt.plot(fpr,tpr,color='darkorange',label='SVM model (area = %0.2f)' % area)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--',label='Random prediction')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
#plt.savefig('ROC-curve-SVC-on-classifing-lethality-using-PI-SL.png',format='png',dpi=300,transparent=False)
<matplotlib.legend.Legend at 0x186c654c908>
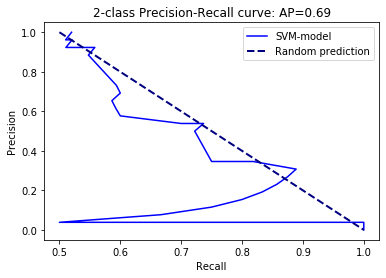
precision, recall, thresholds = metrics.precision_recall_curve(y_test, scores)
average_precision = metrics.average_precision_score(y_test, scores)
plt.plot(precision,recall,color='blue',label='SVM-model')
plt.plot([0.5, 1], [1, 0], color='navy', lw=2, linestyle='--',label='Random prediction')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('2-class Precision-Recall curve: '
'AP={0:0.2f}'.format(average_precision))
plt.legend()
#plt.savefig('Precision-Recall-curve.png',format='png',dpi=300,transparent=False)
<matplotlib.legend.Legend at 0x186c62aaa48>
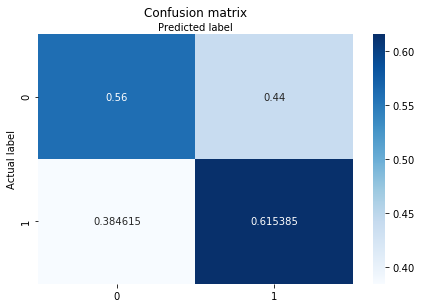
class_names=[1,2,3]
fig, ax = plt.subplots()
from sklearn.metrics import confusion_matrix
import sklearn.metrics as metrics
cm = confusion_matrix(y_test, y_pred,normalize="true")
class_names=['SL', 'nSL']
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
sns.heatmap(pd.DataFrame(cm), annot=True, cmap="Blues" ,fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
#plt.savefig('confusion-matrix-normalized.png',format='png',dpi=300,transparent=False)
Text(0.5, 257.44, 'Predicted label')
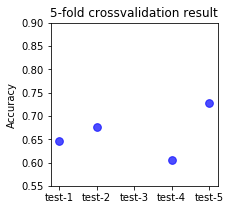
2.3.6. Step of crossvalidation to evaluate the peformance of the classifier in terms of overfitting¶
(Caution!) Highly time consuming ~2h for 10000 X 3072 matrix
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import cross_val_score
import time
n_samples = X.shape[0]
t = time.process_time()
cv=StratifiedKFold(n_splits=5)
elapsed_time = time.process_time() - t
print('The elapsed time was',elapsed_time)
The elapsed time was 0.0
import sklearn.metrics as metrics
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import cross_validate
t = time.process_time()
cv_results = cross_validate(clf, X, y, cv=cv)
elapsed_time = time.process_time() - t
print('The elapsed time was',elapsed_time)
The elapsed time was 0.71875
#saving the results
dump(cv_results, '../cross_val_object_5_fold_clf_model.joblib')
['../cross_val_object_5_fold_clf_model.joblib']
from joblib import dump, load
#loading the crossvalidation
cv=load('../cross_val_object_5_fold_clf_model.joblib')
2.3.7. Viz of the variation of the test error per fold . If the variation is high , the classifier may be proned to overfitting.¶
fig, axs = plt.subplots(ncols=1, figsize=(3,3))
sorted(cv_results.keys())
plt.scatter(['test-1','test-2','test-3','test-4','test-5'],cv_results['test_score'],s=60,alpha=0.7,color='blue')
plt.title('5-fold crossvalidation result')
plt.ylim(0.55,0.9)
plt.ylabel('Accuracy')
#plt.savefig('5-fold-crrosvalidation-result.png', format='png',dpi=300,transparent='true',bbox_inches='tight')
Text(0, 0.5, 'Accuracy')
2.4. Using PCA to reduce the dimensionality of the problem¶
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
scaler = StandardScaler()
model_scaler = scaler.fit(X_train)
# Apply transform to both the training set and the test set.
x_train_S = model_scaler.transform(X_train)
x_test_S = model_scaler.transform(X_test)
# Fit PCA on training set. Note: you are fitting PCA on the training set only.
model = PCA(0.95).fit(x_train_S)
x_train_output_pca = model.transform(x_train_S)
x_test_output_pca = model.transform(x_test_S)
# np.shape(x_train_output_pca)
# np.shape(X_train.T)
np.shape(x_train_S),np.shape(x_test_S),model.components_.shape,np.shape(x_train_output_pca)
((117, 3025), (51, 3025), (97, 3025), (117, 97))
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
parameters = [{'C': [1, 10, 100], 'kernel': ['rbf'], 'gamma': ['auto','scale']}]
search = GridSearchCV(SVC(), parameters, n_jobs=-1, verbose=1)
search.fit(x_train_output_pca, y_train)
Fitting 5 folds for each of 6 candidates, totalling 30 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=-1)]: Done 23 out of 30 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 0.0s finished
GridSearchCV(estimator=SVC(), n_jobs=-1,
param_grid=[{'C': [1, 10, 100], 'gamma': ['auto', 'scale'],
'kernel': ['rbf']}],
verbose=1)
best_parameters = search.best_estimator_
print(best_parameters)
SVC(C=100)
from sklearn import svm
clf_after_pca = svm.SVC(C=10, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False).fit(x_train_output_pca, y_train)
clf_after_pca.score(x_test_output_pca, y_test)
0.5686274509803921
from joblib import dump, load
dump(clf_after_pca, '../model_SVC_C_10_gamma_scale_kernel_rbf_10000x1622_after_PCA_matrix.joblib')
['../model_SVC_C_10_gamma_scale_kernel_rbf_10000x1622_after_PCA_matrix.joblib']
from sklearn import metrics
from sklearn.metrics import log_loss
from sklearn.metrics import jaccard_score
y_pred_after_pca = clf_after_pca.predict(x_test_output_pca)
# print('Train set Accuracy: ', metrics.accuracy_score(y_train, clf.predict(X_train)))
print('The mean squared error is =',metrics.mean_squared_error(y_test,y_pred_after_pca))
print('Test set Accuracy: ', metrics.accuracy_score(y_test, y_pred_after_pca))
print('The Jaccard index is =', jaccard_score(y_test, y_pred_after_pca))
# Jaccard similarity coefficient, defined as the size of the intersection divided by the size of the union of two label sets. The closer to 1 the better the classifier
print('The log-loss is =',log_loss(y_test,y_pred_after_pca))
# how far each prediction is from the actual label, it is like a distance measure from the predicted to the actual , the classifer with lower log loss have better accuracy
print('The f1-score is =',metrics.f1_score(y_test,y_pred_after_pca))
# The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal.
# Model Precision: what percentage of positive tuples are labeled as such?
print("Precision:",metrics.precision_score(y_test, y_pred_after_pca))
# Model Recall: what percentage of positive tuples are labelled as such?
print("Recall:",metrics.recall_score(y_test, y_pred_after_pca))
The mean squared error is = 0.43137254901960786
Test set Accuracy: 0.5686274509803921
The Jaccard index is = 0.18518518518518517
The log-loss is = 14.899095691871866
The f1-score is = 0.3125
Precision: 0.8333333333333334
Recall: 0.19230769230769232
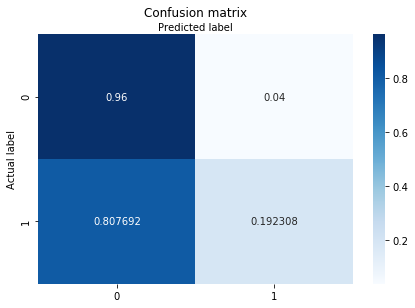
class_names=[1,2,3]
fig, ax = plt.subplots()
from sklearn.metrics import confusion_matrix
import sklearn.metrics as metrics
cm = confusion_matrix(y_test, y_pred_after_pca,normalize="true")
class_names=['SL', 'nSL']
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
sns.heatmap(pd.DataFrame(cm), annot=True, cmap="Blues" ,fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
Text(0.5, 257.44, 'Predicted label')
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_after_pca, target_names=['NonSl','SL']))
precision recall f1-score support
NonSl 0.53 0.96 0.69 25
SL 0.83 0.19 0.31 26
accuracy 0.57 51
macro avg 0.68 0.58 0.50 51
weighted avg 0.69 0.57 0.50 51